
| 문제집 | 만든이 | 문제수 | 조회수 | 좋아요 | 생성 | 수정 | 공개 |
|---|---|---|---|---|---|---|---|
| 블록 코딩 : 08. Text | 관리자 | 0 | 5288 |  0 0
| 2019-02-07 01:16:53 |
2019-02-09 09:57:12 |
2019-03-31 23:56:13 |
텍스트는 큰 따옴표(")로 묶여진 문자열입니다. 다음은 텍스트의 예입니다.
- "물건 #1"
- "2010년 3월 12일"
- "" (빈 텍스트)
- " " (공백 텍스트)
텍스트에는 문자 (소문자 또는 대문자), 숫자, 구둣점, 기타 기호 및 단어 사이의 공백을 포함할 수 있습니다.
텍스트 생성
다음은 텍스트 "hello"를 생성하고 이를 greeting 변수에 저장합니다.
![]()
다음은 2개의 텍스트를 서로 '연결'하는 경우로서, greeting 변수에 저장된 텍스트와 "world" 텍스트를 연결한 새로운 텍스트를 만듭니다. 2개의 기존 텍스트에 공백이 없으므로, 새롭게 만들어지는 텍스트에서 공백이 없음을 확인해 보세요.

연결하고자 하는 텍스트를 추가하려면 톱니 아이콘을 클릭해서 다음과 같이 변경합니다. 즉, 왼쪽 회색 영역에 있는 item 블록은 오른쪽 join 블록으로 드래그하여 추가하면 됩니다.
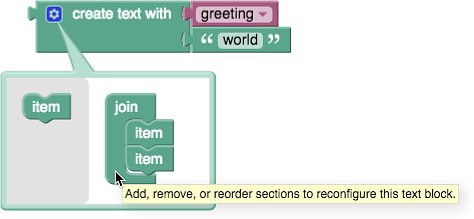
텍스트 변경
to ... append text 블록은 변수에 텍스트를 추가합니다. 다음의 프로그램은 greeting 변수에 저장된 텍스트 "hello" 다음에 ", there!"를 추가해서 "hello, there!"를 만듭니다.
![]()
텍스트 길이
length of 블록은 주어진 텍스트의 길이를 계산합니다. 텍스트 "We're #1!"의 길이는 9이고(We're와 #1! 사이에 1개의 공백이 포함되어 있음), 빈 텍스트의 길이는 0 입니다.
![]()
![]()
빈 텍스트 확인
is empty 블록은 주어진 텍스트가 비어있는지 검사합니다. 다음의 첫번째 블록은 true, 두번째 블록은 false 입니다.
![]()
![]()
텍스트 찾기
다음은 텍스트의 일부가 다른 텍스트에 존재하는지, 존재한다면 그 위치는 어디인지 확인합니다. 첫번째 블록은 "hello"에서 "e"가 처음 나오는 위치를 확인합니다. 결과는 2입니다.
![]()
다음은 "hello"에서 "e"가 맨 마지막에 나오는 위치를 확인합니다. 역시 결과는 2 입니다.
![]()
다음은 "hello"에서 "z"가 존재하지 않으므로, first, last 중 어떤 것을 선택하든, 결과는 0 입니다.

단일 문자 추출
다음은 "abcde"의 두번째 문자인 "b"를 얻습니다.
![]()
다음은 "abcde"의 마지막 글자 중 두번째 문자인 "d"를 얻습니다.
![]()
다음은 "abcde"의 첫번째 문자인 "a"를 얻습니다.
![]()
다음은 "abcde"의 마지막 문자인 "e"를 얻습니다.
![]()
다음은 동일한 확률로 "abcde"의 5글자 중 하나를 얻습니다.
![]()
텍스트 영역 추출
택스트 내의 특정 구간을 지정하여 출력할 수도 있습니다.
시작 위치
- letter # : 특정 위치
- letter # from end : 뒤에서부터 특정 위치
- first letter : 첫번째 위치
종료 위치
- letter # : 특정 위치
- letter # from end : 뒤에서부터 특정 위치
- last letter : 마지막 문자

대/소문자 변경
다음의 3가지 방법으로 대/소문자 변경이 가능합니다.
- UPPER CASE : 모두 대문자
- lower case : 모두 소문자
- Title case : 첫 글자는 대문자, 다른 글자는 소문자

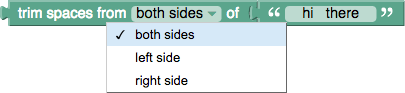
공백 제거
다음의 3가지 방법으로 공백 문자를 제거합니다.
- both sides : 텍스트의 양쪽 공백 제거
- left side : 텍스트의 왼쪽 공백 제거
- right side : 텍스트의 오른쪽 공백 제거
| 코드 | 제목 | 시간(초) | 메모리(MB) | 나의판정 | 소스 | 제출 회 | 통과 회 | 비율(%) | 시도 명 | 성공 명 | 비율(%) | ||