
| DNA 유사도 |
|---|
모든 생물의 DNA 서열은 A, C, G, T 네 개의 문자로만 표현된다. 한 DNA 서열에서 두 문자의 거리 는 두 문자 사이에 있는 문자들의 개수이다. DNA 서열의 부분서열은 DNA 서열에서 몇 개의 문자를 제 거하여 얻을 수 있는 서열을 말한다. 예로 DNA 서열 AGTCAC에서 두 번째 문자 G와 다섯 번째 문자 A의 사이에는 두 개의 문자 'TC'가 있기 때문에 이 두 문자의 거리는 2이다. 또한 이 DNA 서열에서 세 번째 문자 T와 네 번째 문자 C를 제거하면 부분서열 AGAC를 얻을 수 있다. K가 0이상인 정수일 때, K-부분서열이란 부분서열에서 이웃한 모든 두 문자가 원래 DNA 서열에서 거리가 최대 K인 부분서열이다. DNA서열 AGTCAC의 부분서열 AGAC에서 인접한 두 문자인, 두 번째 문자 G와 세 번째 문자 A는 원래 DNA 서열에서 각각 두 번째와 다섯 번째 문자이고 두 문자 사이에는 두 개의 문자 'TC'가 있으므로 AGCATA의 1-부분서열이 될 수 없으나 2-부분서열은 된다. 두 DNA 서열이 얼마나 비슷한가를 측정하기 위하여 사용하는 방법 중에 하나는 최장 공통 K-부분서 열을 찾는 것이다. (놀랍게도 인간과 쥐의 DNA 서열은 90%이상이 동일하다고 한다.) 두 DNA 서열의 최장 공통 K-부분서열이란 두 서열에서 모두 얻을 수 있는 동일한 K-부분서열 중, 가장 길이가 긴 부 분서열을 말한다. 최장 공통 K-부분서열은 여러 개 있을 수 있다.
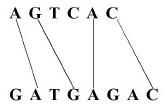
예를 들어서, 위 그림과 같이 두 DNA 서열 AGTCAC와 GATGAGAC가 주어진 경우, AGAC는 최장 공통 2-부분서열은 되지만, 1-부분서열은 될 수 없다. 왜냐하면 DNA 서열 AGTCAC에서 2번째 문자인 G와 5번째 문자인 A사이에 두 개의 문자 'TC'가 있기 때문이다. GTAC도 최장 공통 2-부분서열이다. 최장 공통 1-부분서열은 AGC, GTA, ATA 세 개가 된다. 이 세 개를 사전식(dictionary) 순서로 나열하면 AGC, ATA, GTA가 된다. 두 DNA 서열과 K가 주어진 경우 두 서열의 최장 공통 K-부분서열을 찾는 프로그램을 작성하시오. |
| 입력 | |
|---|---|
첫째 줄에는 K(0≤K≤30)가 입력된다. 둘째 줄에 는 첫째 DNA 서열의 길이를 나타내는 정수가 입력된다. DNA 서열의 길이는 1,000이하이다. 셋째 줄에 는 첫째 DNA 서열이 주어진다. 넷째 줄에는 둘째 DNA 서열의 길이를 나타내는 정수가 주어진다. 다섯 번째 줄에는 둘째 DNA 서열이 주어진다. 단, DNA 서열을 나타내는 문자들 사이에 공백은 없다. | |
| 출력 | |
|---|---|
주어진 두 DNA 서열의 최장 공통 K-부분서열을 출력한다. 답이 여러 개이면 사전식 순서로 가장 앞에 있는 서열을 출력한다. | |
| 예시 | |||
|---|---|---|---|
| 1 | 입력 | 1 6 AGTCAC 8 GATGAGAC | |
| 출력 | AGC | ||